Saliency Prototype for RGB-D and RGB-T Salient Object Detection
ACM International Conference on Multimedia 2023
Zihao Zhang, Jie Wang, Yahong Han,
College of Intelligence and Computing, and Tianjin Key Lab of Machine Learning, Tianjin University
Abstract
Most of the existing bi-modal (RGB-D or RGB-T) salient object detection methods attempt to integrate multimodality information through various fusion strategies. However, existing methods lack a clear definition of salient regions before feature fusion, which results in poor model robustness. To tackle this problem, we propose a novel prototype, the saliency prototype, which captures common characteristic information among salient objects. A prototype contains inherent characteristics information of multiple salient objects, which can be used for feature enhancement of various salient objects. By utilizing the saliency prototype, we provide a clearer definition of salient regions and enable the model to focus on these regions before feature fusion, avoiding the influence of complex backgrounds during the feature fusion stage. Additionally, we utilize the saliency prototypes to address the quality issue of auxiliary modality. Firstly, we apply the saliency prototypes obtained by the primary modality to perform semantic enhancement of the auxiliary modality. Secondly, we dynamically allocate weights for the auxiliary modality during the feature fusion stage in proportion to its quality. Thus, we develop a new bi-modal salient detection architecture Saliency Prototype Network (SPNet), which can be used for both RGB-D and RGB-T SOD. Extensive experimental results on RGB-D and RGB-T SOD datasets demonstrate the effectiveness of the proposed approach against the state-of-the-art.
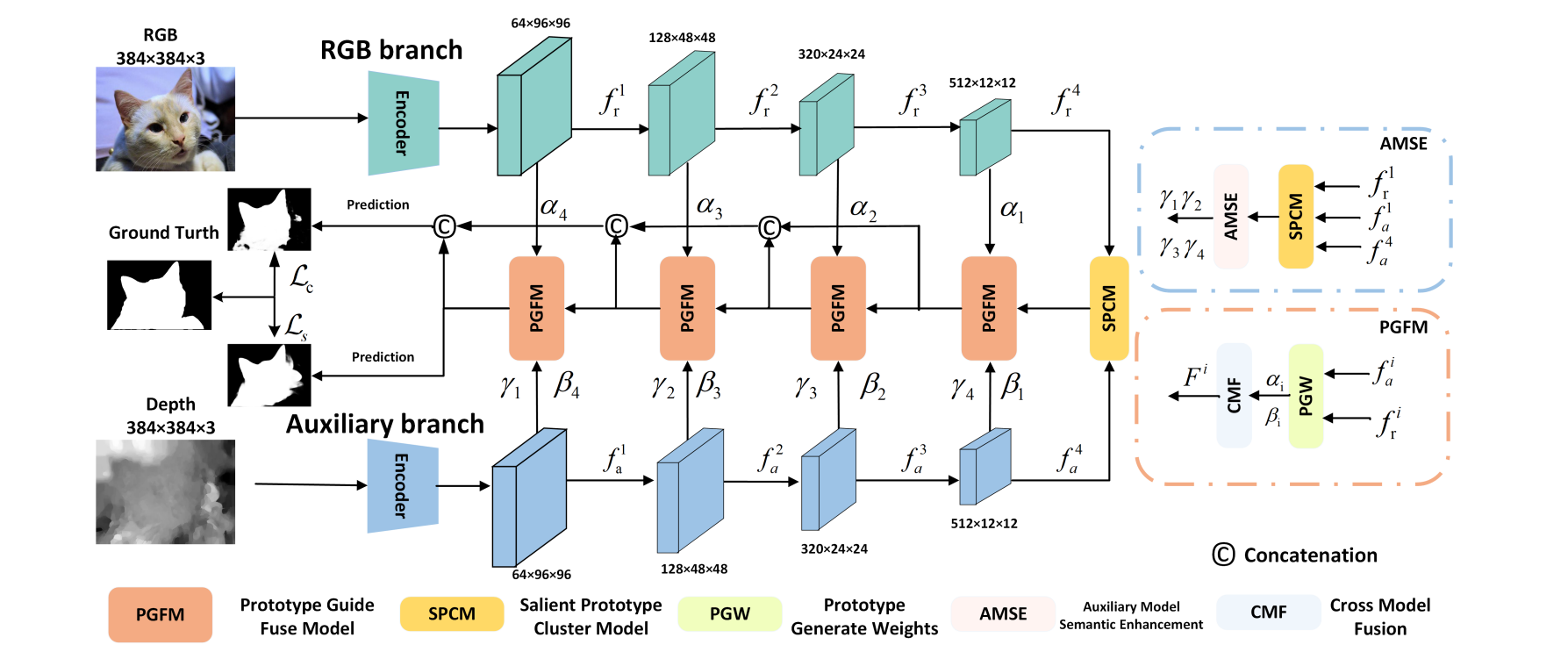
Overall architecture of the Saliency Prototype Network
 |
|---|
Fig. 1: Overall architecture of the Saliency Prototype Network. After feature extraction, the RGB and D/T images perform prototype clustering separately to focus on salient regions before performing cross-modal feature fusion. On the right side, the AMSE module generates parameters for cross-modal fusion, guiding the fusion process but not directly participating in the overall architecture.
Quantitative Evaluation
 |
|---|
Table. 1: S-measure, adaptive F-measure, adaptive E-measure, MAE comparisons with different RGB-D models. The best result is in bold. "¯¯" means that the method does not publish test results for this dataset or code.
 |
|---|
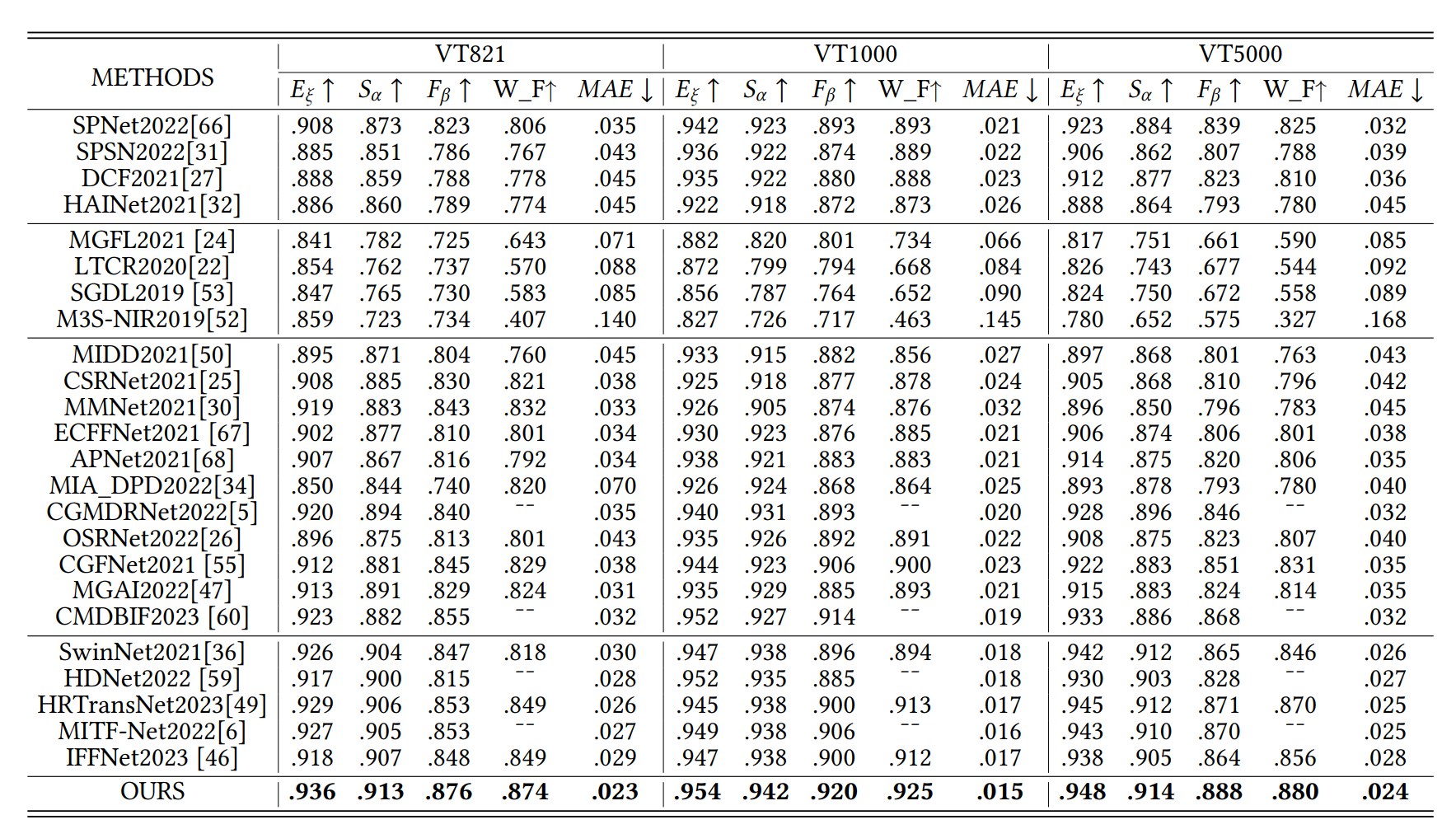
Table. 2: S-measure, adaptive F-measure, adaptive E-measure, MAE comparisons with different RGB-T models. First column represents the RGB-D methods adapted for RGB-T. Second column represents conventional RGB-T methods. Third column represents CNN-based RGB-T methods. Fourth column represents Transform-based RGB-T methods.
 |
|---|
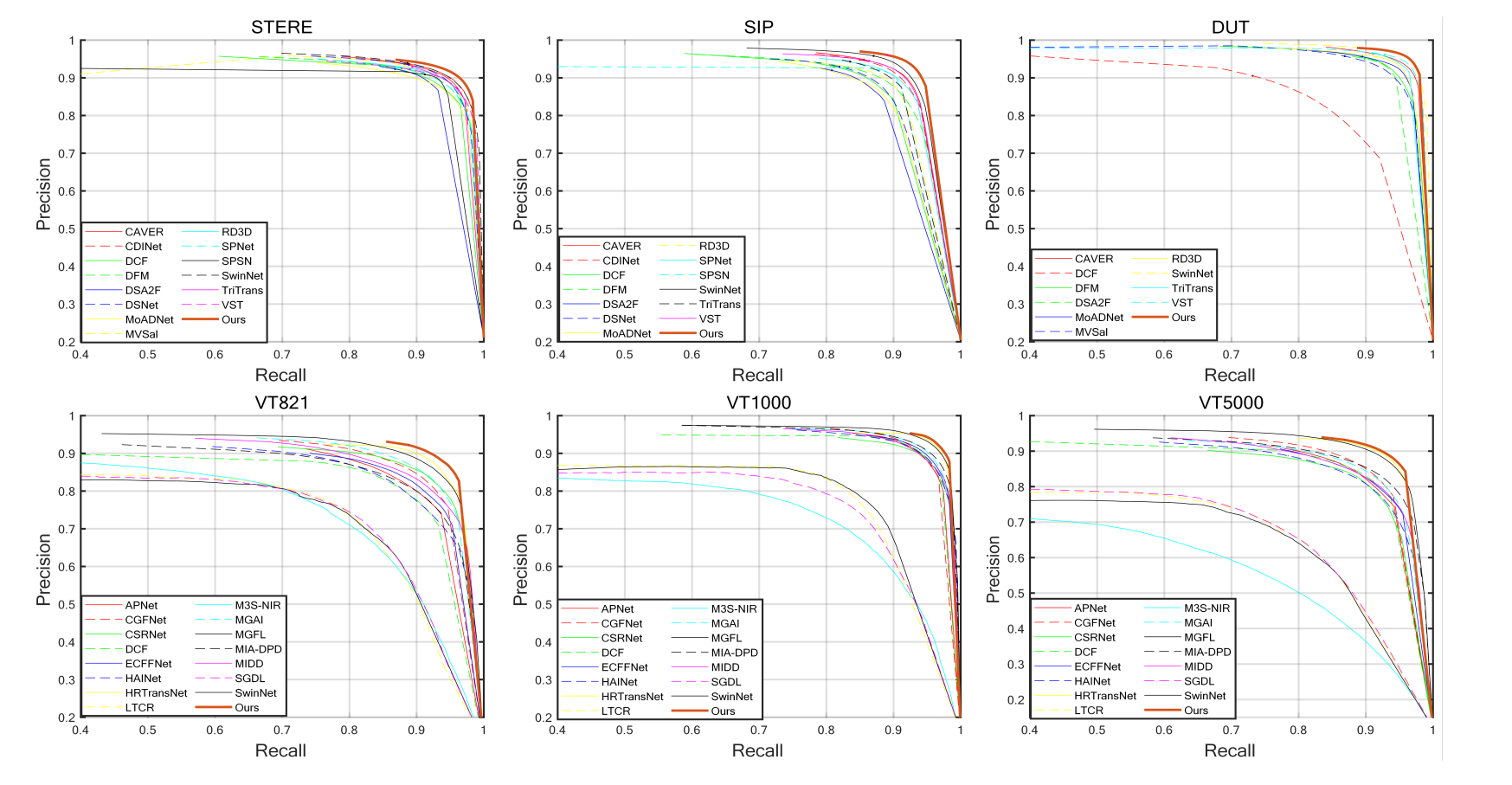
Fig. 2: P-R curves comparisons of different models on six datasets of RGB-D and RGB-T.
